Boostcamp Day 14. 2021-02-04.
Deep Learning Basics - RNN, LSTM, Transformer
Contents
Intro - RNN, LSTM
주식, 언어와 같은 Sequential data와 이를 이용한 Sequential model의 정의와 종류에 대해 배웁니다. 그 후 딥러닝에서 sequential data를 다루는 Recurrent Neural Networks 에 대한 정의와 종류에 대해 배웁니다.
Sequntial Model
Sequential data는 우리가 일상적으로 많이 접하는 data이다. 대화, 비디오 등. Sequential data나 model을 다루는 것은 힘들다. 왜냐하면 앞전의 CNN과 다르게 얼마만큼이 입력값인지 모르고 얼마동안 들어오는지 모른상태로 모델이 동작해야되기 때문이다. 그 상태로 다음 상태를 예측해야하는 거니 어렵죵.
Markov model(first-order autoregressive model)
현재의 나는 바로 전의 과거에 의존적이고 그 과거는 과거의과거에 의존적이다. 이와같이 sequential data를 다룰 때는 Markov model(first-order autoregressive model)이 활용되기도 한다. 장점은 joint distribution을 활용하는 거지만 한계가 있다. 사실은 과거의 수많은 경험과 요소들이 현재의 나를 만들기 때문이지 바로 직전의 경험이 나를 만들진 않기 때문.
| $p(x_1, \ldots ,x_T) = p(x_T | x_{T-1})p(x_{T-1} | x_{T-2}) \cdots p(x_2 | x_1)p(x_1) = \prod_{t=1}^T p(x_t | x_{t-1})$ |
$\prod$ 이건 s 부터 t까지 모두 곱
Latent autoregressive model
앞에 설명한거의 단점은, 사실 이전에 더 많은 요소를 고려해야 하는데 그렇지 못한것이 단점이다. 그래서 사용하는 것이 이것이다. 중간에 hidden state가 있고 임마는 과거의 정보를 summary하고 있다. 그래서 다음번 time step은 이 하나의 hidden state에만 dependent하다는 것.

$\hat x = p(x_t|h_t)$
$h_t = g(h_{t-1}, x_{t-1})$ $h_t$와 $h_{t-1}$는 Summary of the past 과거에 대한 정보들.
RNN - Recurrent Neural Network
바닐라 RNN이라고도 불림.
Short-term dependencies & Long-term dependencies
RNN이 가진 단점이다. 가장 최근의 정보는 잘 기억하고 잘 적용할 수 있지만, 음성이 길어지거나 문장이 길어지면 먼 과거의 정보를 잃어버린다.
Vanishing & Exploding gradient
[수식] 이처럼 중첩되서 계산이 되는 특성이 있는데, activation function이 sigmod일 경우 값이 계속해서 0 ~ 1사이로 중첩되서 Gradient가 Vanishing되는 문제가 있고, 반대로 ReLU같은 경우는 0 이상이면 계속해서 상수배 곱해지기 때문에 Gradient가 Exploding 폭발해버리는 문제가 잇다.
그래서 바로 LSTM이 나온것임.
LSTM - Long Short Term Memory
Walk Through
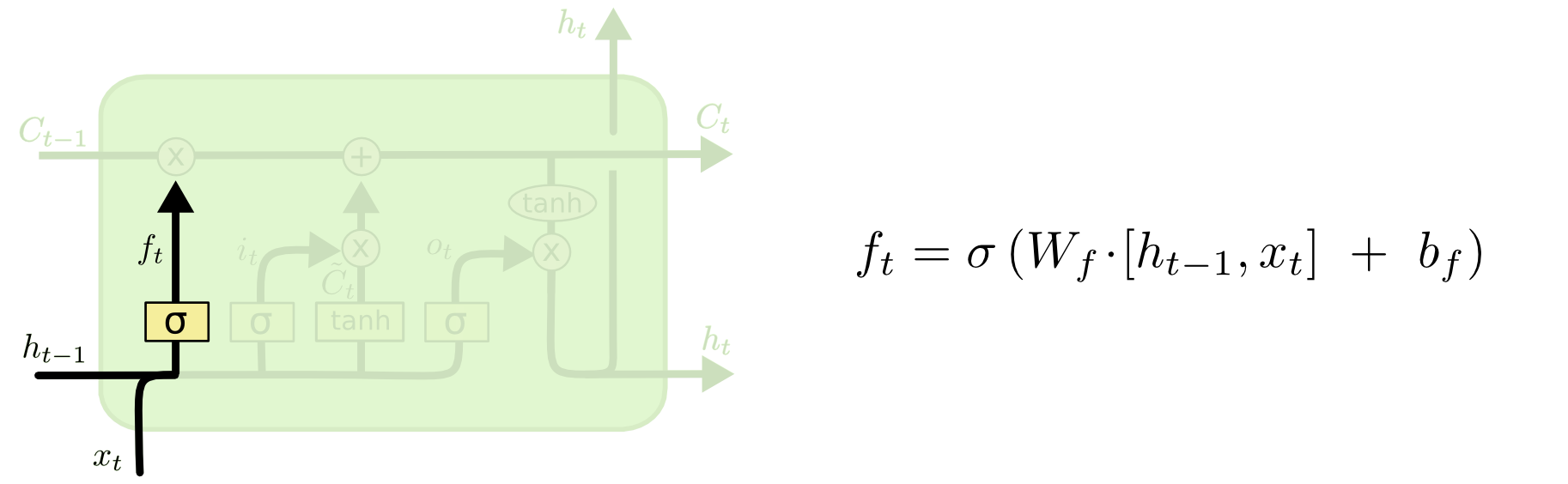
Forget Gate
- Decide which information to
throwaway.
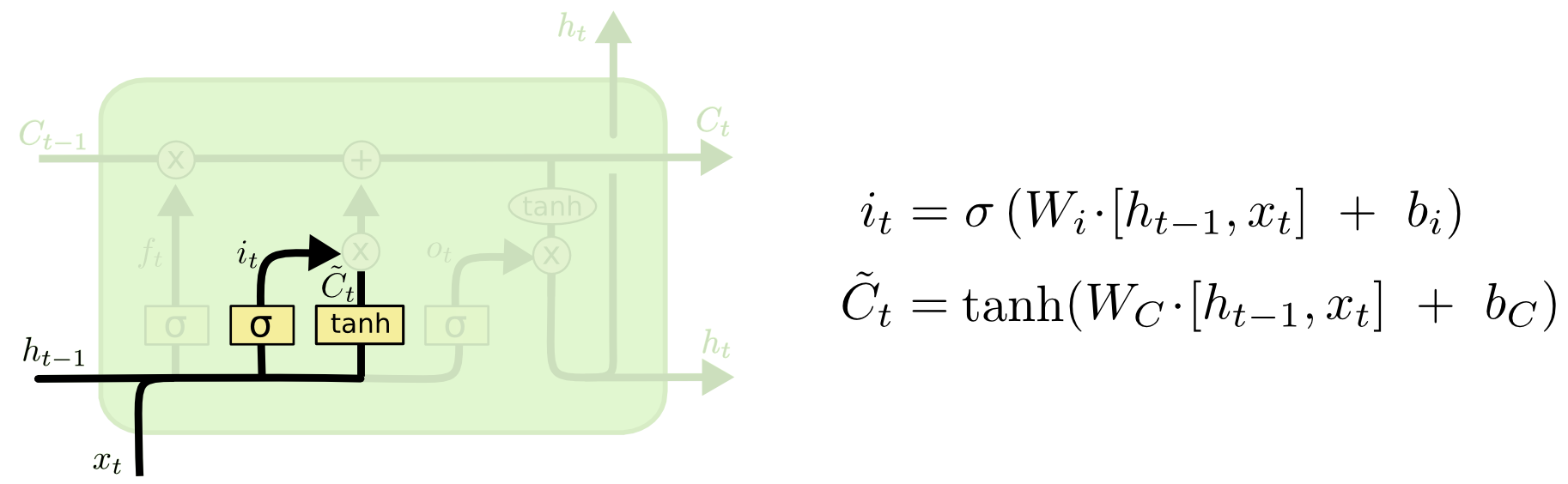
Input Gate
- Decide which information to
storein the cell state.
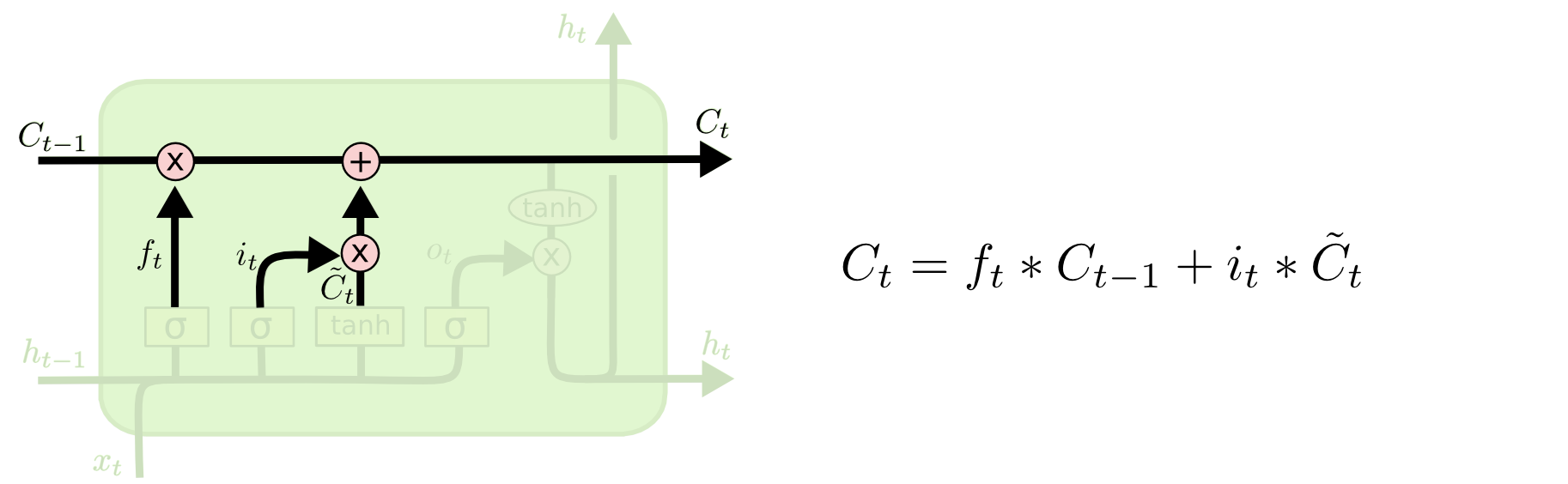
Update cell
Update the cell state.
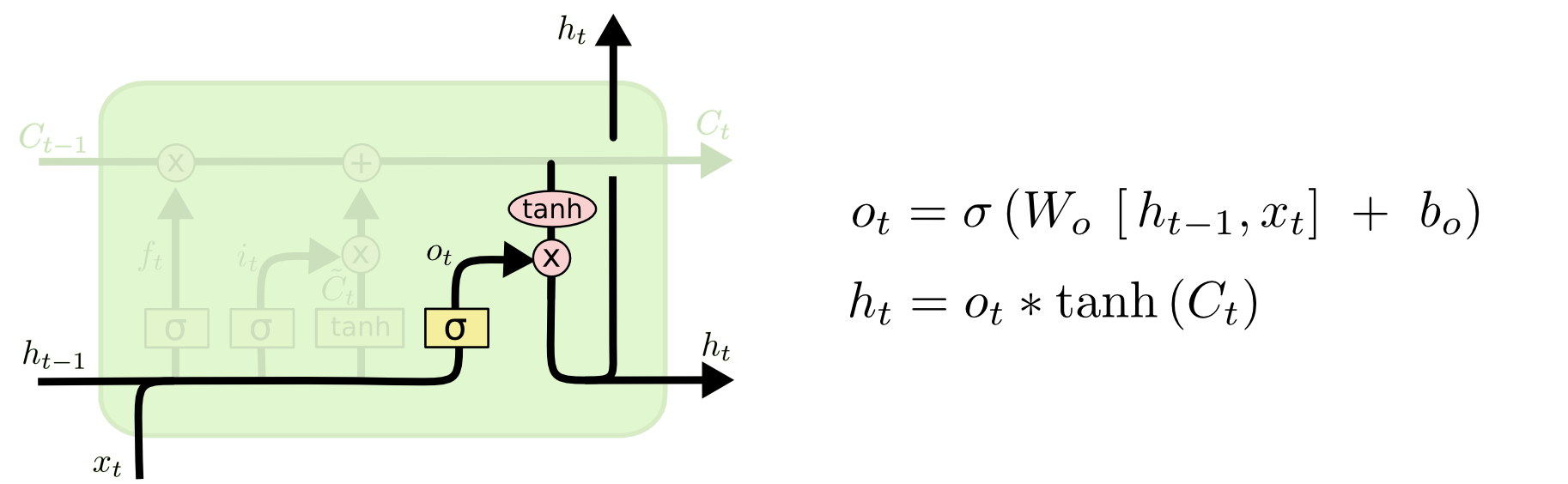
Output Gate
- Make output using the updated cell state.
To Summarize

GRU - Gated Recurrent Unit

- Simpler architecture with two gates(rest gate and update gate)
- No cell state, just hiden state.
Intro - Transformer
Sequential model의 한계점과 이를 해결 하기 위해 등장한 Transformer에 대해 배웁니다. Transformer는 Encoder와 Decoder로 구성되어있지만 강의에서는 Encoder와 Multi Head Attention 에 대해 좀 더 집중적으로 배웁니다.
Transformer
Transformer is the first sequence transduction model base entirely on attention.
기존의 RNN은 재귀적인 느낌으로 돌아가는 거라고 하면 트렌스포머는 Attention이라 불리우는 구조를 활용한다.
![]()
- Transformer encodes each word to feature vectors with
Self-Attention.
3개의 단어가 벡터로 self-attntion에 들어가면 3개의 벡터가 나오는데 그냥 나오는 것이 아니라 첫번째 벡터여도 두번째 세번째 벡터의 정보를 들고 어텐션에 들어가서 그 정보와 함께 틔어나온다. 그래서 서로 나머지 단어들과 연관이 있으니깐Dependencies가 있다고 말함. 그 다음

Feed-forward paths are word-independent, and parallelized.
말인 즉슨, 그렇게 틔어나온 벡터들은 Feed-forward 단에서는 독립적으로 각각 병렬적으로 들어간다는 뜻.
Suppose we are encoding two words
- Self-Attention at a high level
- EX) The animal didn’t cross the street because it was too tired. it 이 무엇을 지칭하는지 어캐알까?
Transformer Encoding 순서(?)

- 단어가 Input된다.
- Embedding을 해서 vector형식으로 만든다
- 각 단어마다 NN을 거쳐서 Queries, Keys, Values 벡터를 만든다.
- 각각의 단어는 Query vector, Key vector를
내적해서 Score를 갖고 잇다. (내적이니깐차원이 같아야함) - 이 스코어를 key의 길이에 루트씌운 값으로 나눈다. Normalize 하는거죵.
- 그리고 나눈 값을 Softmax를 활용해서 0 ~ 1사이 값으로 만들고
- Softmax 값과 value를 곱해서 백터를 만든다. 요단계가 The final encoding is done by the
weighted sum of the value vectors.
value vector의 weighte를 구하는 과정이 각 단어에서 나오는 Query vector 와 Key Vector 사이의 내적, 그것을 Normalize하고 Softmax취해줘서 나오는 Attention을 Value vector와 Weighted Sum(Broadcasting)을 한게 최종적으로 나오는 Thinking이란 단어의 Encoding된 벡터가 되는거.

수식으로 표현하면
${Attention(Q, K, V) = } {softmax \left( {QK^T} \over {\sqrt{d_k}} \right)}$
Calculating Q,K, and V from X in a matrix form.
Transformer의 한계
메모리 많이 먹고 시간 오래걸림. 왜냐하면 N개의 입력값이 있다고하면 RNN은 재귀적으로 N번 돌면서 결과를 구하지만. 트렌스포머는 N*N으로 변환해서 돌리기 때문에 입력값이 커지면 오래걸리고 그만큼 자원도 많이 잡아 먹는다. 그럼에도 불구하고 유연하고 더 많은 표현력을 갖을 수 있기 때문에 좋음.
Multi-headed Attention
- Multi-headed Attention(MHA) allows Transformer to focus o ndiffernet positions.
어텐션을 여러번 하는거임. 앞에 꺼는 하나의 단어에서 enbedding해서 나온 쿼리 키 벡터를 하나만 만드는게 아니라 N개면 N개 만들어서 사용하는거. 그래서 머리가 여러개라는 뜻을 사용하나봄.
if eight heads are used, we end up getting eight differnt sets of encoded vectors(attention heads). N개의 Attention을 사용하게 되면 N개의 Encoding된 벡터를 얻을 수 있다.
- We simply pass them through additional (learnable) linear map.
- 1) concatenate all the attention heads
- 2) Multiply with a weight matrix $W^o$ that was trained jointly with the model.
- 3) The result would be the $Z$ matrix that captures information from all the attention heads. We can send this forward to th FFNN.
Encoding Process
![]()
- get input sentence.
- We embed each word
- Split into 8 heads. We multiply
XorRwith weight matrices. - Calculate attention using the resulting
Q/K/V. - Concatenate the resulting
Zmatrices, then multiply with weight matrix $W^o$ to produce the output of the layer.
-
Why do we need positional encoding? 어떤 단어가 먼저 들어가고 나중에 들어가고하는것이 중요하기 때문에 포지션 인코딩이 필요하다. 같은 단어라고 하더라도 들어가는 순서에 따라 어텐션이 달라진다(?) 무튼 임베딩된거에 값을 더한다는거. so Positional encodings are
addedto the original embedding. - What is the information being sent from encoders to decoders?
TransformertransfersKey(K)andValue(V)of the topmost encoder to the decoder.-
the output sequence is generated in an autoregressive manner. 최종적으로 나오는 값은 인코더에서 나오는 키와 벨류 벡터를 이용해서 디코딩하면 하나의 단어씩 만들게 됨.
-
In the
Decoder, the self-attention layeris only allowed to attend to earlier positions in the output sequence which is done by masking future positions before the softmax step. 학습단계에서 masking을 하는데 이유는 정답을 알고 있으면 안되니깐 뒤에 있는 거를 잠시 못본척? 앞에 단어만 dependent 하다. - The
"Encoder-Decoder Attention"layer works just like multi-headed self-attention, except it creates itsQueriesmatrix from the layer below it, and takes thekeysandvaluesfrom the encoder stack.
Further Questions
- Pytorch에서 Transformer와 관련된 Class는 어떤 것들이 있을까요?
- DALL-E - 문장을 이미지로 만들어 주는거. GPT-3 사용해서 만들었다는데 내부적으론 Transfer가 있데.
- LSTM에서는 Modern CNN 내용에서 배웠던 중요한 개념이 적용되어 있습니다. 무엇일까요?
- Pytorch LSTM 클래스에서 3dim 데이터(batch_size, sequence length, num feature),
batch_first관련 argument는 중요한 역할을 합니다.batch_first=True인 경우는 어떻게 작동이 하게되는걸까요?
Reference
- bootcamp AI Tech pdf.
- NAVER Connect Foundation.
- paper : Attention is All you need
- Illustrated-Transformer by JayAlammar
- Sequence Models - dive into DL
- LSTM-blog
- LSTM and GRU
- cs224n