Boostcamp Day 23. 2021-02-24.
Graph in AI - Recommendation System
Contents
- 내용기반 추천(Contents based Recommendation)
- 협업 필터링(Collaborative Filtering)
- 추천 시스템의 평가
Intro
넷플릭스와 유투브의 컨텐츠 추천, 아마존의 상품 추천 등 우리는 일상생활 속 다양한 곳에서 추천 시스템을 사용하고 있습니다. 이번 강의에서는 다양한 형태의 추천시스템 중 아이템의 내용을 사용해 추천해주는 '내용 기반 추천(contents based recommendation')과, 유저와 아이템간의 유사도를 통해 추천을 해주는 '협업 필터링(collaborative filtering)'에 대해 공부해봅니다. 각 알고리즘의 장단점에 집중하면서 강의를 들어봅시다!
추천 시스템은 사용자 각각이 구매할 만한 혹은 선호할 만한 상품/영화/영상을 추천합니다.
Graph 관점에서 추천 시스템은
미래의 간선을 예측하는 문제혹은누락된 간선의 가중치를 추정하는 문제로 해석할 수 있음.
내용 기반 추천시스템(Contents based Recommendation)
내용기반 추천은 각 사용자가 구매/만족햇던 상품과 유사한 것을 추천하는 방법.
ex)
- 동일한 장르의 영화를 추천하는 것
- 동일한 감동의 영화 혹은 배우가 출현한 영화를 추천.
- 동일한 카테고리의 상품을 추천하는 것.
원리
- 첫 단계로 사용자가 선호했던 상품들의
상품 프로필(Item Profile)을 수집하는 단계.- 상품 프로필이란, 해당 상품의 특성을 나열한
벡터임
- 상품 프로필이란, 해당 상품의 특성을 나열한
- 다음 단계는
사용자 프로필(User Profile)을 구성하는 단계입니다.- 사용자 프로필은 선호한 상품의 상품 프로필을 선호도를 사용하여 가중 평균하여 계산한다. 즉 사용자 프로필 역시 벡터임.
- 다음 단계는 사용자 프로필과 다른 상품들의 상품 프로필을 매칭하는 단계.
- 사용자 프로필 벡터 $\vec u$와 상품 프로필 벡터 $\vec v$
코사인 유사도$\vec u \cdot \vec v \over {\lVert \vec u \rVert \lVert \vec v \rVert}$ 를 계산합니다. 즉, 두 벡터의 사이각의 코사인 값을 계산합니다.- 각이 좁을 수록 유사도가 높은거고 각이 크면 유사도가 낮은거임.
장단점
장점
- 다른 사용자의 구매 기록이 필요없다.
- 독특한 취향의 사용자에게도 추천이 가능하다
- 새 상품에 대해서도 추천이 가능하다
- 새 상품이 벡터화 되어있다면
- 추천의 이유를 제공할 수 있다.
- 예를들어 특정 장르의 영화를 봤기 때문에 비슷한 장르를 추천하는 경우
단점
- 상품에 대한 부가 정보가 없는 경우에는 사용할 수 없다.
- 구매 기록이 없는 사용자에게는 사용할 수 없다.
- 과적합(Overfitting)으로 지나치게 협소한 추천을 할 위험이 있다.
협업 필터링(Collaborative Filtering)
협업 필터링의 핵심은 유사한 취향의 사용자를 찾는 것이다.
주로 3단계로 이뤄지는데
추천의 대상을 x라고 한다면
- 우선 x와 유사한 취향의 사용자들을 찾는다
- 다음 단계로 유사한 취향의 사용자들이 선호한 상품을 찾는다.
- 마지막으로 이 상품들을 x 에게 추천한다.
그런데 취향의 유사도는 어떻게 계산할까?
바로
상관 계수(Correlation Coefficient)를 통해 측정합니다.

구체적으로
취향의 유사도를 가중치로 사용한 평점의가중 평균을 통해 평점을 추정합니다.
-
사용자 $x$의 상품 $s$에 대한 평점을 $r_{xs}$를 추정하는 경우를 생각해 봅시다.
-
앞서 설명한 상관 계수를 이용하여 상품 $s$를 구매한 사용자 중에 x와 취향이 가장 유사한 $k$명의 사용자 $N(x;s)$를 뽑습니다.
-
평점 $r_{xs}$는 아래의 수식을 이용해 추정합니다.
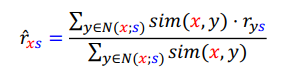
- 즉,
취향의 유사도를 가중치로 사용한 평점의 가중 평균을 계산합니다.
마지막 단계는
추정한 평점이 가장 높은 상품을 추천하는 단계임.
추천의 대상인 어떤 사용자가 아직 구매하지 않은 상품 각가에 대해 평점을 추정한다.
추정한 평점이 가장 높은 상품을 사용자에게 추천한다.
장단점
(+) : 상품에 대한 부가 정보가 없는 경우에도 사용할 수 있다.
(-) : 충분한 수의 평점 데이터가 누적되어야 효과적입니다.
(-) : 새 상품, 새로운 사용자에 대한 추천이 불가능 하다.
(-) : 독특한 취향의 사용자에게 추천이 어렵다.
추천 시스템의 평가
추정한 평점과 실제 평가 데이터를 비교하여 오차를 측정한다.
-
Mean Squared Error, MSE(평균 제곱 오차)를 오차를 측정하는 지표로 사용.
- ${1\over \lvert T \rvert} \sum_{r_{xi} \in T} (r_{xi} - \hat r_{xi})^2$
-
Root Mean Squared Error, RMSE(평균 제곱근 오차)도 많이 사용됨.
- 위에식에서 $\sqrt MSE$ 씌워준거.
$T$ : 평가 데이터 내의 평점들의 집합을 말함.
이 밖에도 다양한 지표가 사용됨.
- 추정한 평점으로 순위를 매긴 후, 실제 평점으로 매긴 순위와의 상관계수를 계산하기도 함.
- 추천한 상품 중 실제 구매로 이루어진 것의 비율을 측정하기도 합니다.
- 추천의 순서 혹은 다양성까지 고려하는 지표들도 사용됩니다.
6강 정리
- 우리 주변의 추천 시스템
- Amazon.com, 넷플릭스, 페이스북, 유투브 등
- 내용 기반 추천 시스템
- 장점 : 새로운 상품에 대한 추천이 가능
- 단점 : 상품에 대한 부가 정보가 있는 경우에만 사용 가능
- 협업 필터링
- 장점 : 부가 정보가 없는 경우에도 사용 가능
- 단점 : 새로운 상품에 대한 추천이 불가능
- 추천 시스템의 평가
- 학습/평가 데이터 분리, 평균 제곱(근) 오차
Reference
- bootcamp AI Tech pdf .
- NAVER Connect Foundation.